Turkish i in C#
By Tan Lee Published on Nov 10, 2024 605
In C#, when working with string comparisons that involve Turkish characters, such as the Turkish lowercase 'i' (ı) and uppercase 'I' (İ), special attention is needed because of the unique way these characters behave in Turkish language and culture.
When comparing a parameter with a literal value, it's common to convert the values to either uppercase or lowercase for consistency. While this approach often works, it does not guarantee 100% accuracy. The issue arises because certain characters may behave unexpectedly when transformed, leading to potential mismatches.
Here's an example that highlights this problem.
string arg = "FoxLearn";
if (arg.ToUpper() == "FOXLEARN")
Debug.WriteLine(arg);
else
throw new InvalidOperationException();In Turkish, the ToUpper("i") method in C# can throw an exception or behave unexpectedly because it returns İ (dotted uppercase I) instead of I (dotless uppercase I). This is due to the unique handling of the letter 'i' in Turkish, which has four distinct forms:
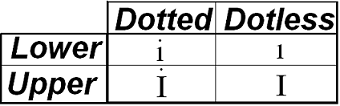
In C#, you can use the InvariantCulture version of the `ToUpper()` and `ToLower()` methods, namely `ToUpperInvariant()` and `ToLowerInvariant()`. These methods perform case conversions without considering culture-specific rules. It's generally recommended to use `ToUpperInvariant()` over `ToLowerInvariant()` to avoid unexpected behavior, especially in scenarios where case conversions might affect logic or data handling. The InvariantCulture ensures consistent behavior regardless of the system's locale.
// Set current culture to Turkey
Thread.CurrentThread.CurrentCulture = new CultureInfo("tr-TR");
string str = "i";
Debug.WriteLine(str.ToUpper()); // İ
Debug.WriteLine(str.ToUpperInvariant()); // I
str = "I";
Debug.WriteLine(str.ToLower()); // ı
Debug.WriteLine(str.ToLowerInvariant()); // iThe first example can be rewritten in several different ways, using various methods or approaches to achieve the same result.
// Use ToUpperInvariant
if (arg.ToUpperInvariant() == "FOXLEARN")
// Use Equals with InvariantCultureIgnoreCase
if (arg.Equals("Login", StringComparison.InvariantCultureIgnoreCase))
// Use Equals with OrdinalIgnoreCase
if (arg.Equals("FOXLEARN", StringComparison.OrdinalIgnoreCase))ToUpperInvariant() and Equals with the InvariantCultureIgnoreCase option generally work well for case-insensitive comparisons. However, InvariantCulture has its own limitations. One issue is that certain characters can be interpreted differently. For example, the combination of \u0061\u030a (a letter 'a' with a ring above it) is interpreted as \u00e5 (the Scandinavian letter 'å'), which might not be the desired behavior in all cases.
InvariantCulture uses a culture-specific table to compare characters and interpret them linguistically, considering locale-specific rules. In contrast, Ordinal performs a byte-by-byte comparison without considering cultural differences. OrdinalIgnoreCase works similarly to Ordinal, but it ignores case for alphabetic characters ([A-Z] and [a-z]). For characters outside the [A-Z] range, OrdinalIgnoreCase uses the InvariantCulture table to look up uppercase and lowercase equivalents, rather than performing a simple byte comparison.
The best approach for the first example code is to use `Equals(OrdinalIgnoreCase)`. This method performs a fast, case-insensitive comparison without relying on culture-specific rules, offering a simple and efficient solution for most scenarios. It ensures that only alphabetic characters' case is ignored, while other characters are compared based on their byte values, providing consistent and predictable results.
Categories
Popular Posts

Structured Data using FoxLearn.JsonLd
Jun 20, 2025

Implement security headers for an ASP.NET Core
Jun 24, 2025

Modernize Material UI Admin Dashboard Template
Nov 19, 2024

SB Admin Template
Nov 14, 2024

RuangAdmin Template
Nov 13, 2024